|
I'm a Research Scientist at Meta Reality Labs. I'm based in scenic Seattle. I recently completed my PhD from the Robotics Institute, School of Computer Science, Carnegie Mellon University advised by Abhinav Gupta and Shubham Tulsiani. I am engaged in the quest for understanding intelligence by trying to simulate it. Although this quest has kept me fully occupied for the past several years, I also paint and write poems, and have a Bachelor of Arts degree in Fine Arts. Some of my paintings can be found here, and poems here. Bio / EMail / Github / GScholar / Twitter / Name / Art / Poem |
refresh page to see homangas in different environments
|
|
|
|
If you have any questions / want to collaborate, feel free to send me an email! I am always excited to learn more by talking with people. Please include "HELLOHOMANGA" in the subject of the email so that I don't miss it. |
|
I'm interested in developing embodied AI systems capable of helping us in the humdrum of everyday activities within messy rooms, offices, and kitchens, in a reliable, compliant, and scalable manner without requiring significant embodiment-specific data collection and task-specific heuristics. A major thrust of my research is on combining robot-specific data with predictive planning from diverse web videos such as YouTube clips of humans doing daily chores and human interaction data obtained through wearables, for developing robust robot learning algorithms deployable in the real-world and compliant with human preferences. I have eclectic research interests, and have also worked on robustness in machine learning, and improving sample efficiency, and representations in reinforcement learning. In my research, I conduct experiments across robot embodiments for demonstrating generalization of policies to unseen tasks including those involving manipulation of completely unseen object types with novel motions. Here are some glimpses of common goal/langauge-conditioned policy deployments in unseen offices and kitchens: |
|
Glimpse of robot deployment results from my works (Gen2Act, Track2Act, HOPMan, RoboAgent). Each robot is controlled with a single goal-conditioned policy where the goal is either an image or a language description specifying the task, and deployed in unseen offices and kitchens. |
|
|
|
|

|
Uksang Yoo, Mengjia Zhu, Evan Pezent, Jom Preechayasomboon, Jean Oh, Jeffrey Ichnowski, Amir Memar, Ben Abbatematteo, Homanga Bharadhwaj, Ashish Deshpande, Harsha Prahlad RSS 2026 paper website SoftAct enables functional retargeting from virtual human demos to soft robot hands by reasoning about contact geometry and force distribution. |

|
Hongyi Chen, Tony Dong, Tiancheng Wu, Liquan Wang, Yash Jangir, Yaru Niu, Yufei Ye, Homanga Bharadhwaj, Zackory Erickson*, Jeffrey Ichnowski* arXiv 2026 paper website We propose VideoManip: a device-free framework that learns dexterous manipulation directly from RGB human videos by reconstructing 3D hand-object interaction trajectories for policy learning. |

|
Anurag Bagchi, Zhipeng Bao, Homanga Bharadhwaj, Yu-Xiong Wang, Pavel Tokmakov, Martial Hebert arXiv 2026 paper website We develop a scalable recipe for converting pre-trained video models to ego-centric world models, capable of diverse OOD manipulation and navigation. |

|
Mingfei Chen, Yifan Wang, Zhengqin Li, Homanga Bharadhwaj, Yujin Chen, Chuan Qin, Ziyi Kou, Yuan Tian, Eric Whitmire, Rajinder Sodhi, Hrvoje Benko, Eli Shlizerman, Yue Liu arXiv 2026 paper website EgoMan: Motion cues from human videos + Reasoning from VLMs enables future 3D hand trajectory prediction in-the-wild for novel tasks in novel scenes. |

|
Irmak Guzey, Haozhi Qi, Julen Urain, Changhao Wang, Jessica Yin, Krishna Bodduluri, Mike Lambeta, Lerrel Pinto, Akshara Rai, Jitendra Malik, Tingfan Wu, Akash Sharma, Homanga Bharadhwaj ICRA 2026 paper website AINA is a framework for building multi-fingered robot manipulation policies directly by watching videos of humans with Aria glasses on, without any robot interaction/tele-operation/simulation data. |

|
Chaoyi Pan, Changhao Wang, Haozhi Qi, Zixi Liu, Homanga Bharadhwaj, Akash Sharma, Tingfan Wu, Guanya Shi, Jitendra Malik, Francois Hogan arXiv 2025 paper website SPIDER is a physics-based retargeting framework to transform and augment kinematic-only human demonstrations to dynamically feasible robot trajectories at scale. By aligning human motion and robot feasibility at scale, SPIDER offers a general, embodiment-agnostic foundation for humanoid and dexterous hand control. |

|
Sungjae Park, Homanga Bharadhwaj, Shubham Tulsiani ICRA 2026 paper website DemoDiffusion is a simple and scalable method for enabling robots to perform manipulation tasks by imitating a single human demonstration, without requiring any paired human-robot data or reinforcement learning. The key idea is to refine a re-targeted human trajectory using a pre-trained generalist diffusion policy. |

|
Hongyi Chen, Yunchao Yao*, Yufei Ye, Homanga Bharadhwaj, Jiashun Wang, Shubham Tulsiani, Zackory Erickson, Jeffrey Ichnowski arXiv 2025 paper website Humans grasp objects with a purpose! Web2Grasp enables such functional grasping for dexterous robot hands via hand-object reconstruction from web images - without requiring any robot teleop data collection for imitation learning. |

|
Chen Bao, Jiarui Xu, Xiaolong Wang*, Abhinav Gupta*, Homanga Bharadhwaj* TMLR, 2025 paper website We develop an in-context action prediction assistant for daily activities. HandsOnVLM enables predicting future interaction trajectories of human hands in a scene given high-level colloquial task specifications in the form of natural language. |

|
Homanga Bharadhwaj, Debidatta Dwibedi, Abhinav Gupta, Shubham Tulsiani, Carl Doersch, Ted Xiao, Dhruv Shah, Fei Xia, Dorsa Sadigh, Sean Kirmani CoRL 2025 paper website video Casting language-conditioned manipulation as human video generation followed by closed-loop policy execution conditioned on the generated video enables solving diverse real-world tasks involving object/motion types unseen in the robot dataset. |

|
Homanga Bharadhwaj, Roozbeh Mottaghi*, Abhinav Gupta*, Shubham Tulsiani* ECCV 2024 paper website We can train a model for embodiment-agnostic point track prediction from web videos combined with embodiment-specific residual policy learning for diverse real-world manipulation in everyday office and kitchen scenes. The resulting goal-conditioned policy can be zero-shot deployed in unseen scenarios. |

|
Homanga Bharadhwaj*, Jay Vakil*, Mohit Sharma*, Abhinav Gupta, Shubham Tulsiani, Vikash Kumar ICRA 2024 Robot Learning Workshop, NeurIPS 2023 (Outstanding Presentation Award) paper website data We can develop a single robot manipulation agent capable of over 38 tasks across 100s of scenes, through semantic augmentations for multiplying data, and action chunking transformers for fitting the multi-modal data distribution. |

|
Homanga Bharadhwaj, Abhinav Gupta*, Vikash Kumar*, Shubham Tulsiani* ICRA 2024 (Best Paper in Robot Manipulation Finalist) paper website video Learning interaction plans from diverse passive human videos on the web, followed by translation to robotic embodiments can help develop a single goal-conditioned policy that scales to over 100 diverse tasks in unseen scenarios, including real kitchens and offices. |

|
Homanga Bharadhwaj, Abhinav Gupta, Shubham Tulsiani*, Vikash Kumar* Pretraining for Robotics Workshop, ICRA 2023 (Spotlight Talk) RAP4 Workshop, ICRA 2023 (Spotlight Talk) paper website Learning to predict plausible hand motion trajectories from passive human videos on the web, followed by transformation of the predictions to a robot's frame of reference enables zero-shot coarse-manipulation with real-world objects. |

|
Mandi Zhao, Homanga Bharadhwaj, Vincent Moens, Shuran Song, Aravind Rajeswaran, Vikash Kumar Pretraining for Robotics Workshop, CoRL 2022 (Spotlight Talk) paper website Through effective augmentations enabled by recent advances in generative modeling, we can develop a framework for learning robust manipulation policies capable of solving multiple tasks in diverse real-world scenes. |
|
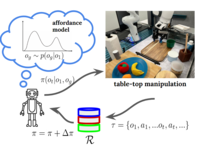
Homanga Bharadhwaj, Abhinav Gupta, Shubham Tulsiani ICRA 2023 paper website We can enable goal-directed robot exploration in the real world by learning an affordance model to predict plausible future frames given an initial image from passive human interaction videos, in combination with self-behavior cloning for policy learning. |

|
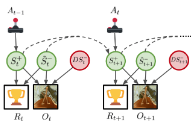
Raj Ghugare, Homanga Bharadhwaj, Benjamin Eysenbach, Sergey Levine, Ruslan Salakhutdinov ICLR 2023 paper website reviews We can learn a latent-space model, and a policy for RL jointly through a single objective, by deriving a lower-bound to the overall RL objective |
|
Homanga Bharadhwaj, Mohammad Babaeizadeh,Dumitru Erhan, Sergey Levine ICLR 2022 paper website reviews Empowerment along with mutual information maximization helps learn functionally relevant factors in visual model-based RL, especially in environments with complex visual distractors. |

|
Homanga Bharadhwaj, Aviral Kumar, Nicholas Rhinehart, Sergey Levine, Florian Shkurti, Animesh Garg ICLR 2021 paper website reviews Training a critic to make conservative safety estimates by over-estimating how unsafe a particular state is, can help significantly minimize the number of catastrophic failures in constrained RL |
|
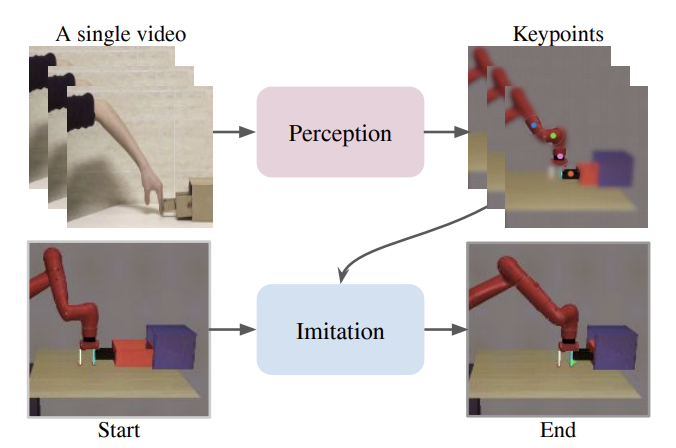
Haoyu Xiong, Quanzhou Li, Yun-Chun Chen, Homanga Bharadhwaj, Samarth Sinha, Animesh Garg IROS 2021 paper website We can learn to imitate human videos for manipulation by extracting task-agnostic keypoints to define an imitation objective that abstracts out aspects of the human/robot embodiment gap. |

|
Kevin (Cheng) Xie*, Homanga Bharadhwaj*, Danijar Hafner, Animesh Garg, Florian Shkurti ICLR 2021 paper website reviews Combining online planning of high level skills with an amortized low level policy can improve sample-efficiency of model-based RL for solving complex tasks, and transferring across tasks with similar dynamics. |
|
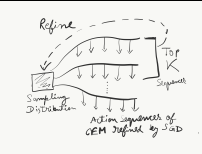
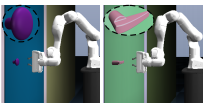
Homanga Bharadhwaj*, Kevin (Cheng) Xie*, Florian Shkurti L4DC, 2020 paper code reviews Updating the top action sequences identified by CEM through a few gradient steps helps improve sample efficiency and performance of planning in Model-based RL |
|
Philip Huang, Kevin (Cheng) Xie, Homanga Bharadhwaj, Florian Shkurti ICRA, 2021 and Deep RL Workshop (NeurIPS 20) paper code video Task-conditioned hypernetworks can be used to continually adapt to varying environment dynamics, with a limited replay buffer in lifelong robot learning |
|
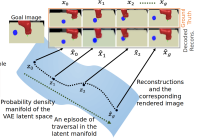
Homanga Bharadhwaj, Animesh Garg, Florian Shkurti ICRA, 2021 paper Keeping track of the currently reachable frontier of states, and executing a deterministic policy to reach the frontier followed by a stochastic policy beyond, can help facilitate principled exploration in RL |
|
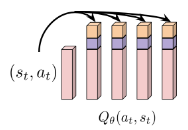
Samarth Sinha*, Homanga Bharadhwaj*, Aravind Srinivas, Animesh Garg Deep RL Workshop (NeurIPS 20) paper blog code reviews Introducing skip connections in the policy and Q function neural networks can improve sample efficiency of reinforcement learning algorithms across different continuous control environments |

|
Homanga Bharadhwaj*, Zihan Wang*, Yoshua Bengio, Liam Paull ICRA 2019 paper video Adversarial domain adaptation can be used for training a gradient descent based planner in simulation and transferrring the learned model to a real navigation environment. |
|
|
|
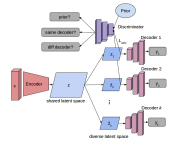
Samarth Sinha*, Homanga Bharadhwaj*, Anirudh Goyal, Hugo Larochelle, Animesh Garg, Florian Shkurti AAAI, 2021 (and ICML-UDL, 2020) paper Explicitly maximizing diversity in ensembles through adversarial learning helps improve generalization, transfer, and uncertainty estimation |
|
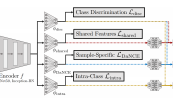
Timo Milbich*, Karsten Roth*, Homanga Bharadhwaj, Samarth Sinha, Yoshua Bengio, Bjorn Ommer, Joseph Paul Cohen ECCV, 2020 paper code Appropriately augmenting training with multiple complimentary tasks can improve generalization in Deep Metric Learning. |
|
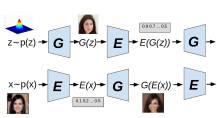
Yatin Dandi, Homanga Bharadhwaj, Abhishek Kumar, Piyush Rai, AAAI, 2021 paper code Adversarially learned inference can be generalized to incorporate multiple layers of feedback through reconstructions, self-supervision, and learned knowledge. |
|
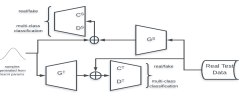
Adversarial Domain Adaptation appropriately incorporated in a Generative Zero Shot Learning model can help minimize domain shift and significantly enhance generalization on the unseen test classes |
|
Homanga Bharadhwaj, De-An Huang, Chaowei Xiao, Anima Anandkumar Animesh Garg Socially Responsible ML Workshop, ICML 2021 (Contributed Talk) paper blog Auditing deep-learning models for human-interpretable specifications, prior to deployment is important in preventing unintended consequences. These specifications can be obtained by considering variations in an interpretable latent space of a generative model. |
|
Homanga Bharadhwaj, Homin Park, Brian Y. Lim RecSys, 2018 paper Recurrent Neural Network based Generative Adversarial Networks can learn to effectively model the latent preference trends of users in time-series recommendation. |
|
|
|
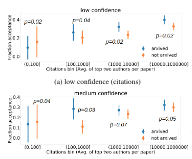
Homanga Bharadhwaj, Dylan Turpin, Animesh Garg, Ashton Anderson arXiv, 2020 paper blog In an analysis of ICLR 2020 and 2019 papers, we find positive correlation between releasing preprints on arXiv and acceptance rates of papers by well-known authors. For well known authors, acceptance rates for papers with arxiv preprint are higher than those without preprints released during review. |
|
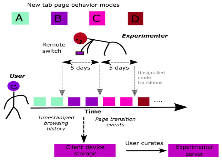
Homanga Bharadhwaj, Nisheeth Srivastava WebSci, 2019 Passive website recommendations embedded in the new tab displays of browsers (that recommend based on frecency) inhibit peoples' propensity to visit diverse information sources on the internet |
|
|
|
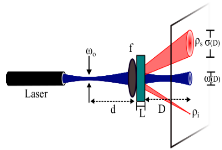
Spontaneous Parametric Down Conversion is used to generate entangled photon pairs. SPDC can be studies through the lens of Wave Optics by making some simplifying theoretical assumptions without compromising on empirical results. Also, a simulation for SPDC can be conveniently designed, given the assumptions. |
|
I love his website design. |