De-anonymization of authors through arXiv submissions during double-blind review
This post is a friendly description and summary of our recent paper titled De-anonymization of authors through arXiv submissions during double-blind review which started as a course project in Ashton Anderson’s amazing course Computational Social Science. The author list for the paper is Homanga Bharadhwaj, Dylan Turpin, Animesh Garg, and Ashton Anderson.
- Introduction
- Research Questions
- Operationalization
- Analyses
- Do papers with arxiv preprints tend to have higher acceptance rates in case of papers by well-known authors?
- Are review scores by less confident reviewers higher in case of papers with high pseudo-reputation and lower in case of papers with low pseudo-reputation?
- Is the effect stronger for borderline papers?
- Discussion
- Limitations
- Acknowledgement
- References
Introduction
In recent times, there has been a rise in the open-access culture of research in Computer Science and many other disciplines. This bas been facilitated in-part by the arxiv e-print repository where researchers can upload research papers either before, during, or after peer-review in a journal/conference with access to anyone in the world without any subscription fee.
In addition to the rise in popularity of arxiv.org, there has been growing consideration regarding reviewer bias in evaluating papers and hence many top CS conferences and journals have moved to a double-blind reviewing system, where both the reviewers’ and authors’ names are witheld from each other. Unfortunately, double-blinding measures are always imperfect. Withholding author names obscures their identity, but can not guarantee that reviewers will not find out who wrote the paper some other way.
In this work, we study one possible source of de-blinding in papers submitted to ICLR, namely arxiv e-prints submitted either before/during double blind peer-review.
Research Questions
We ask the following research question: What is the relation between de-anonymization of authors through arXiv preprints and acceptance of a research paper at a (nominally) double-blind venue?
Operationalization
Here, we describe the operationalization we chose to analyze the research question.
Dataset
The International Conference on Learning Representations (ICLR) is an emerging conference focused on deep learning. ICLR uses the OpenReview platform for open peer review, so all reviews are publicly available for analysis. We choose ICLR data (from 2019 and 2020), because it contains information about acceptances, rejections and reviews of all submitted papers - including author data and affiliations. We scraped data from a total of 5057 submissions, after ignoring papers that were desk rejected or withdrawn prior to decision.
Based on the papers and respective author lists scraped from OpenReview, we searched for papers with the same author list on arXiv, and for papers whose preprint existed on arXiv, we noted down the first upload timestamp.
Corresponding to the author list on all papers scraped from OpenReview for ICLR 2020 and ICLR 2019, we extraced their h-indices and total citations from Google Scholars. Authors who did not have a Google Scholars account we excluded from our analysis.
Measuring paper reputation
To operationalize our research question, we have to choose a reasonable quantitative measure of author reputation, and paper reputation. For the purpose of this study, we define two metrics for the reputation of an author: their h-index and their total citations as calculated by Google Scholar. Since we will be analyzing review outcomes for papers, most of which have multiple authors, we further define two measures for the pseudo-reputation of a paper.
- The average of the h-indices of the top 2 authors of the paper (i.e. the highest and the second highest h-indices in the author list).
- The average of the total citations of the top 2 authors (i.e. the highest and the second highest total citations in the author list) .
The h-index is defined as the maximum value of h such that the given author has published h papers that have each been cited at least h times.
Analyses
In order to better understand our overall research question, we perform analyses in order to answer the following sub-questions
Do papers with arxiv preprints tend to have higher acceptance rates in case of papers by well-known authors?
We plot a histogram with binned paper pseudo-reputation along the x-axis and average % of papers accepted in each bin along the y-axis. We consider two different conditions for the plot:
- only papers released on arXiv before or during the review process, i.e. before the date reviews were released on OpenReview.
- all other papers that are either not present on arXiv or were published on arXiv after the date reviews were released on OpenReview.
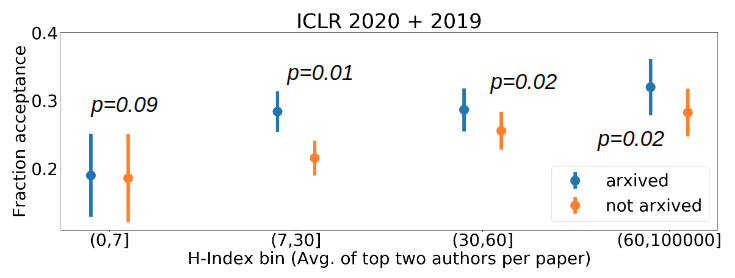
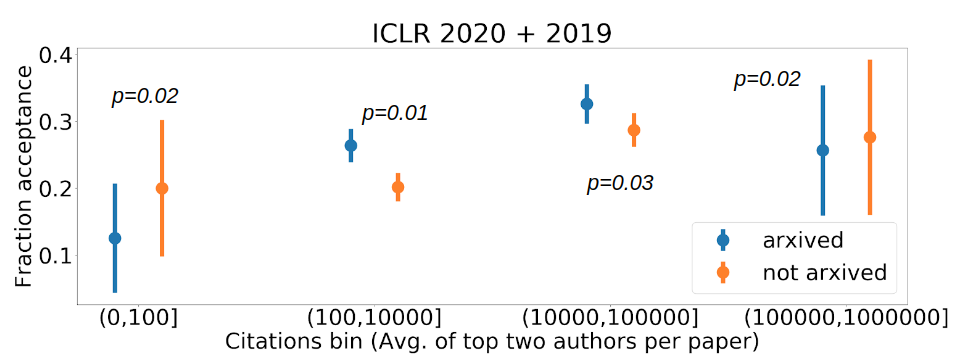
Fig 1. Analysis of fraction acceptance for different bins of paper pseudo-reputation. The pseudo-reputation metric is the (a) average of the top two max. h indices and the (b) average of the top two max. citations of the author list of each paper. To analyze the statistical significance of our results, we conduct one tailed pairwise t-tests between the two conditions for each of the bins and report the p-values in the plots above.
Analyzing Fig. 1, we note that for the first bin, the % acceptance for papers in the not arxived condition is higher than the arxived condition, while in subsequent bins, in particular the third and fourth bins the trend is reversed. Further, these differences are statistically significant and hence we conclude that there is a positive correlation between releasing preprints on arXiv and acceptance rates of papers by well-known authors under our concretization of the problem.
Are review scores by less confident reviewers higher in case of papers with high pseudo-reputation and lower in case of papers with low pseudo-reputation?
While writing reviews for ICLR papers, reviewers must self-specify their confidence in the review of the paper in the form of a field called experience assessment. There are four different confidence levels that reviewers can choose from, for example the highest level is defined by I have read many papers in this area. This is publicly displayed along with the reviews. We denote the numerical value of the confidence scores as 1,2,3,4 (lowest to highest in this order).
We consider bins of paper pseudo-reputations on the x-axis for all papers that have been released on arXiv and plot 3 histograms (corresponding to whether the average reviewer confidence score for the paper lies in low (1,2.5), medium (2.5,3], or high (3,4] categories) indicating the average review score assigned by each category of reviewers to papers in each bin.
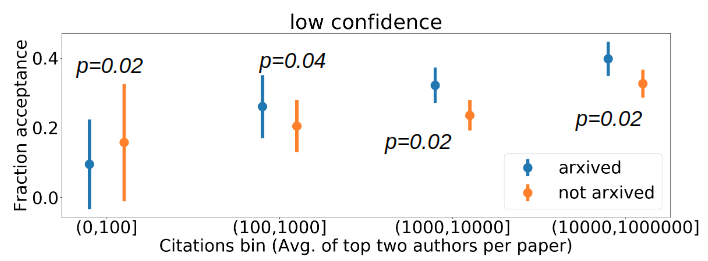
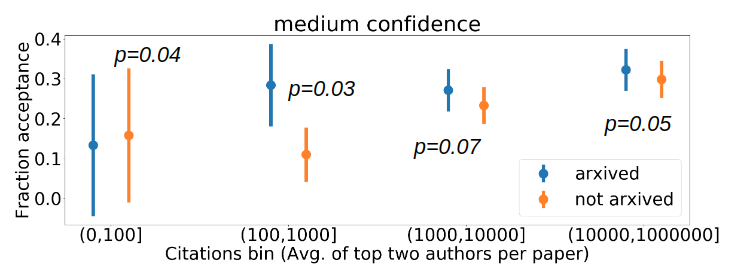
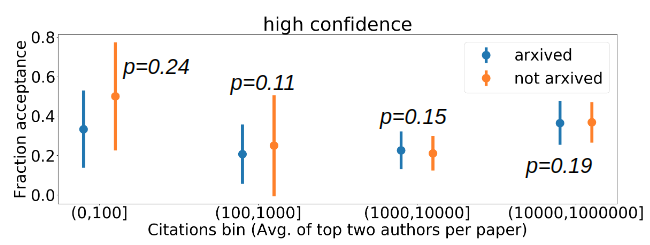
Fig. 2 Analysis of %acceptance for different citation bins of paper pseudo-reputation. The pseudo-reputation metric is the average of the top two max. citations of the author list of each paper and the average reviewer confidence scores are grouped into (a) low, (b) medium, and (c) high categories. To analyze the statistical significance of our results, we conduct one tailed pairwise t-tests between the two conditions for each of the bins and report the p-values in the plots above.
Based on Fig. 2 we obtain statistically significant evidence of negative correlation between confidence of reviewers and their likelihood to assign low review scores to papers with low pseudo-reputation.
Is the effect stronger for borderline papers?
We analyze papers that have a borderline reviewer rating on average and papers that are highly rated by reviewers on average, under the two conditions arxived and not arxived prior to decision notification. This analysis aims to understand the existence of potential bias at the level of Area Chairs.
To have a principled scheme of determining which papers are borderline, we plot fraction acceptance of papers per average reviewer rating bin, where the bins are created based on the twenty percentile values (please refer to our paper for this plot). Based on this, we define borderline papers to be the papers that received an average rating in the range (4.2,6.1) and highly rated papers to be those that received an average rating in the range (6.1,8).
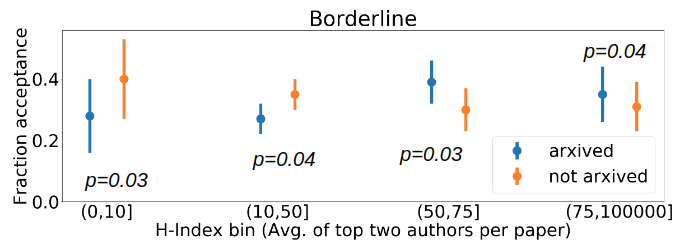
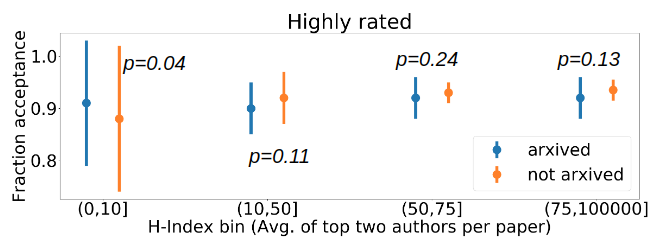
Analysis of %acceptance for different H-Index bins of paper pseudo-reputation. The pseudo-reputation metric is the average of the top two max. h-indices of the author list of each paper. In (top fig.) we analyze borderline papers and in (bottom fig.) we analyze highly rated papers. To analyze the statistical significance of our results, we conduct one tailed pairwise t-tests between the two conditions for each of the bins and report the p-values in the plots above.
Based on Fig. 3, we observe that releasing preprints on arXiv increases acceptance rates of papers by well-known authors, and decreases acceptance rates of papers by less well known authors under our concretization of the problem. Also, the effect is indeed stronger for borderline papers compared to highly rated papers.
Discussion
Given our findings in this study and the implications this must be having in the publication culture of our community, we discuss some solutions to mitigate potential reviewer bias caused by de-anonymization through arXiv preprints. Since the point of a preprint is that the paper is either soon to be submitted for review or is currently under review, arxiv.org could have the option of allowing authors to keep the author list anonymized. Conferences that follow the double blind review system could enforce that only papers that are anonymized on arXiv and that will remain anonymized during the review phase can be submitted to the conference. If the purpose of releasing a preprint is early dissemination of knowledge, having the author list anonymized for some duration would not be detrimental to this cause as the anonymized paper would still be citable (a practice followed by ICLR on OpenReview). In order to strongly discourage people from putting up incomplete works under the cover of anonymity for early flagplanting, strict rules can be enforced regarding the conditions under which a paper submitted on arxiv can be later updated. For example, it can be imposed that papers that are submitted in anonymous format when updated will still display the old version by default and the new version will have a separate upload timestamp and be linked to the old version. i.e. the two versions (anonymous and updated) will be listed as separate papers with their respective timestamps and the anonymous version being the one displayed by default in order to discourage people from trying to flagplant incomplete work.
In addition to the above, we believe it is important to modify the typical peer-review process to have a maximum limit on the number of low confidence reviewers that are assigned to a paper. Since we have observed correlational evidence in that low confidence reviewers are more likely to assign favorable ratings to papers with reputable authors, if possible the number of low confidence reviewers overall in the review process should be decreased and if this is not possible then the number of such reviewers per paper must be limited to atmost one.
Limitations
It is important to note that our study is entirely based on observational data and hence it is not possible for us to make rigorous causal claims. Since the same set of reviewers were not exposed to the two conditions arxiv and no arxiv we cannot make any conclusive claims with respect to the intent or bias of the reviewers. On the other hand, we believe that the in-the-wild nature of our study is helpful in putting into perspective the trends that emerge (albeit correlational and not necessarily causal) in the current publication and preprint culture of machine learning. In addition, it may be the case that more senior researchers (usually having high h-indices and total citations) are likely to have a better understanding of how ready for presentation a particular paper is and hence may be likely to arxiv better papers in general.
Another limitation of our study is that we only analyze data from two recent ICLR conferences (ICLR 2020 and ICLR 2019). ICLR served as the natural platofrm for this study as the entire list of submissions and reviews are publicly released, in the spirit of open science. It would be very helpful if we could validate our claims on other popular CS/AI/ML conferences to understand the interplay of de-anonymization through arXiv and the type of reviews. This is our appeal to the community to consider adopting the OpenReview system and publicly release the entire list of submissions and all the reviews. Apart from facilitating analyses like ours, this also helps readers put into perspective the contributions of the papers and understand the potential shortcomings that were pointed out in the review phase and that hopefully have been addressed in the final version.
Acknowledgement
I thank Samarth Sinha, Shruti Joshi, Bhairav Mehta, Vanessa Khuong, and Kevin Xie for insightful discussions and feedback on the blog post.
References
[1] Tomkins, Andrew, et al. “Reviewer bias in single- versus double- blind peer review” Proceedings of the National Academy of Sciences.
Please contact me at [homanga at cs dot toronto dot edu] if you have any questions regarding this post or if you notice any errors in the same. The blog is designed with Jekyll and Minima. The template has been shamelessly copied from Lilian Weng